Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Local LLM Inference and Fine-Tuning | PDF | Graphics Processing Unit ...
LLM Inference Workload Insights | PDF | Cache (Computing) | Graphics ...
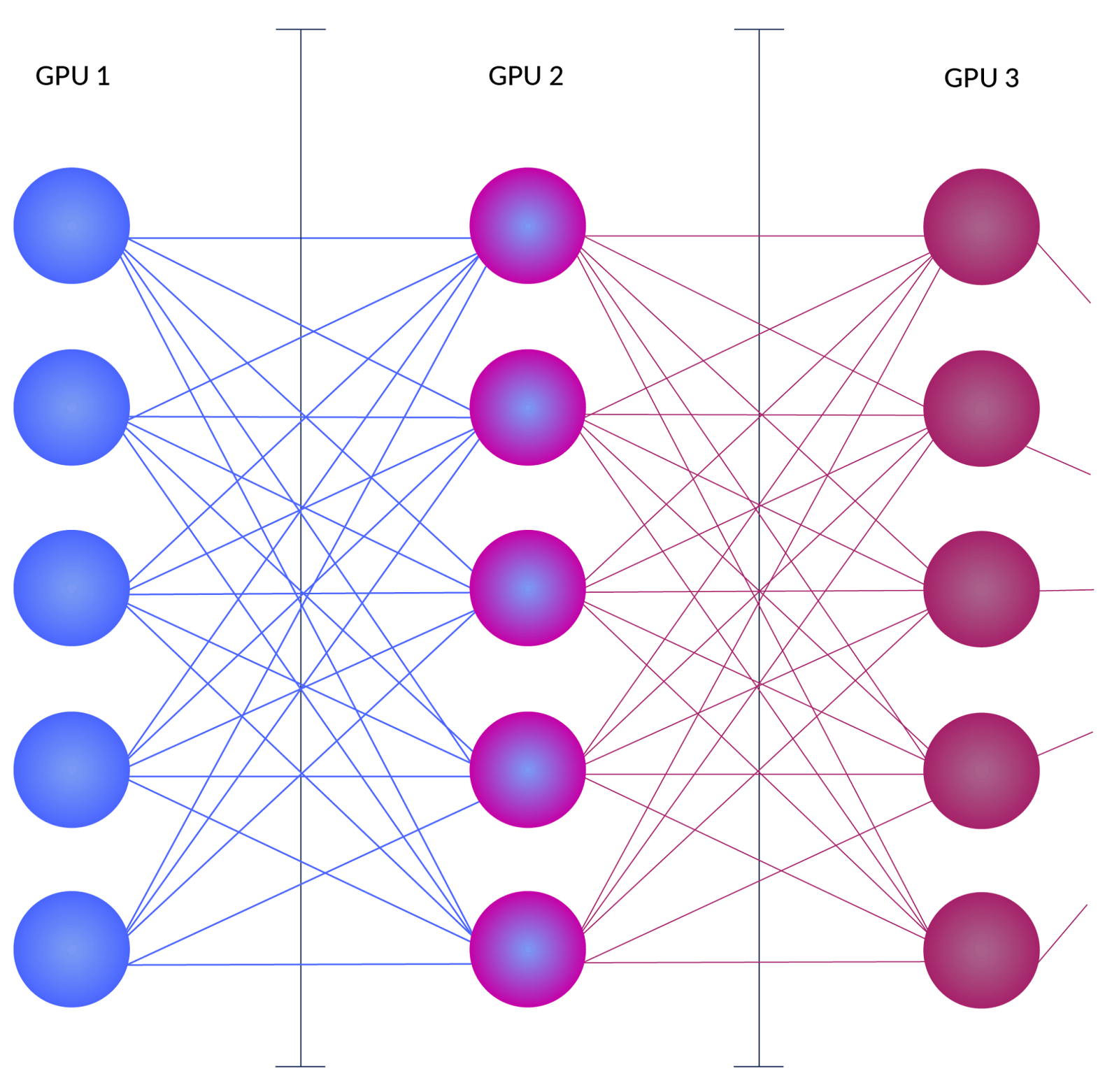
Fast Scaling for LLM Inference | PDF | Scalability | Graphics ...
Understanding LLM Inference - by Alex Razvant
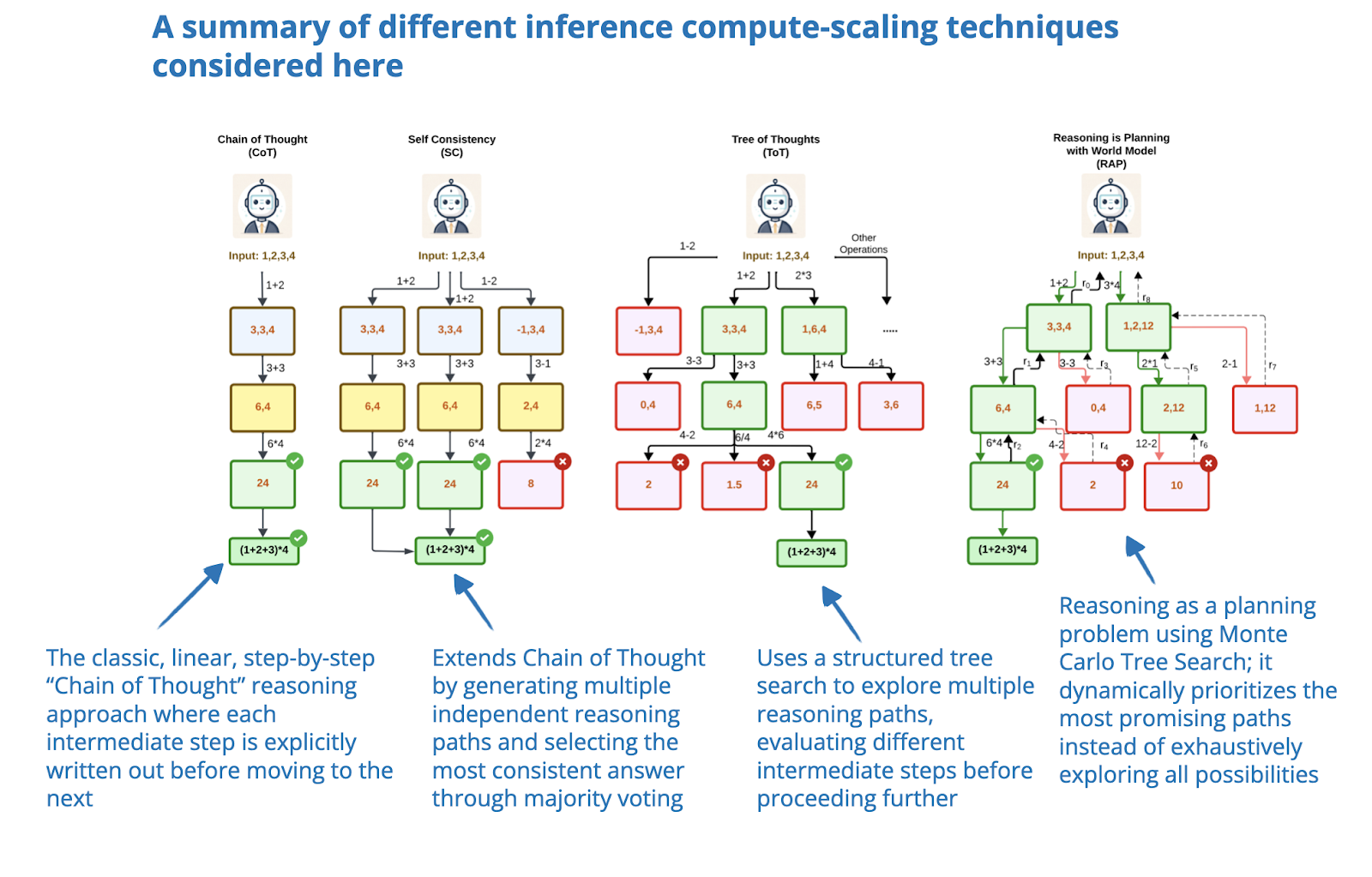
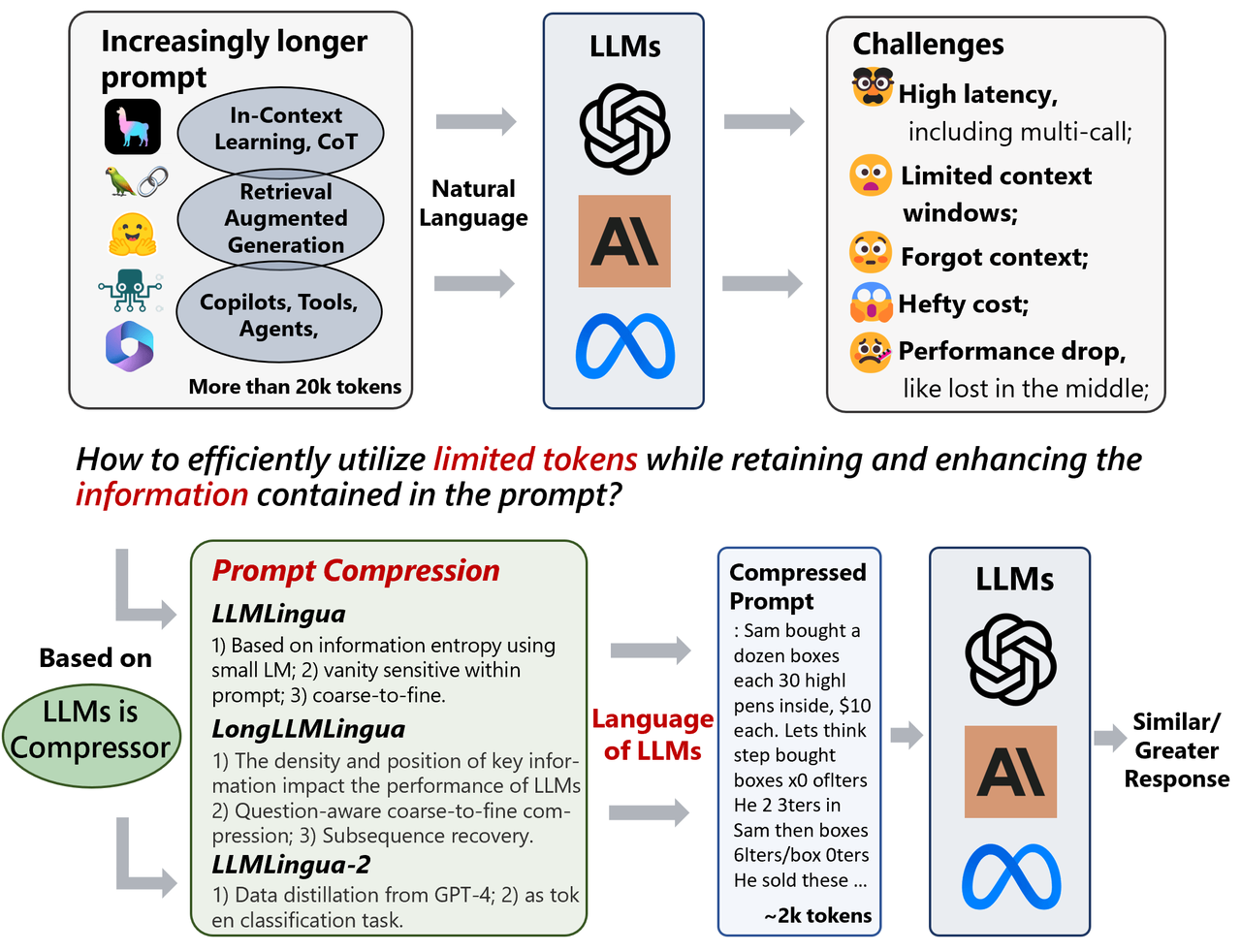
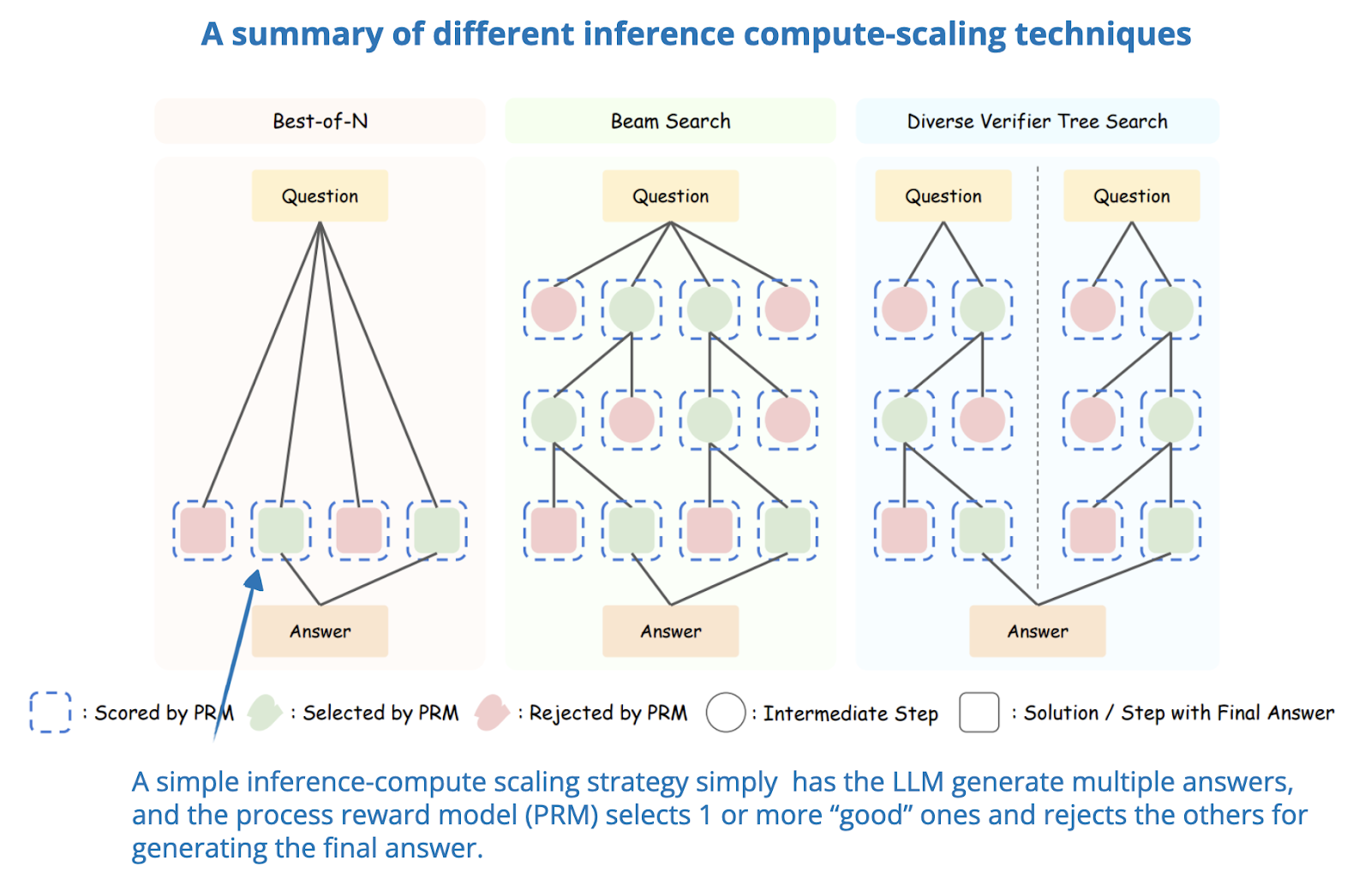
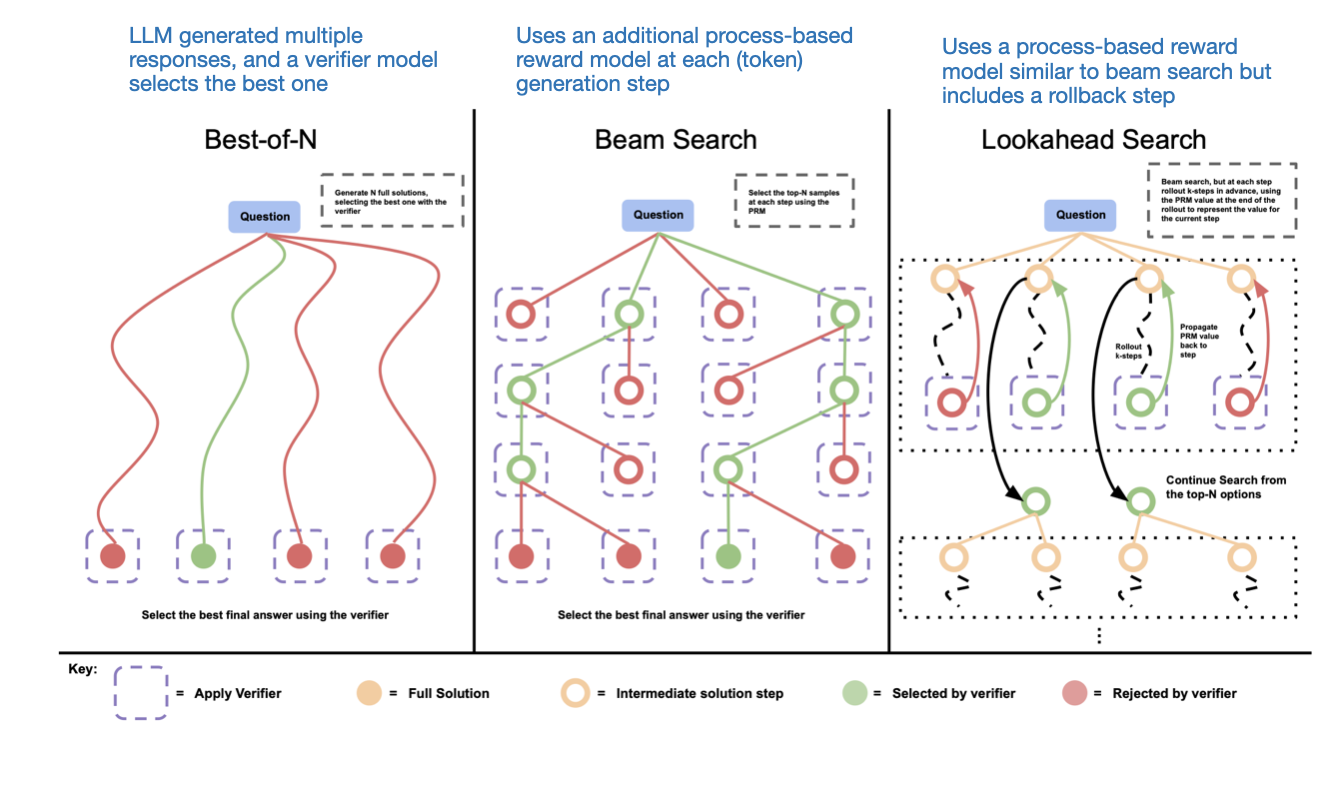
The State of LLM Reasoning Model Inference
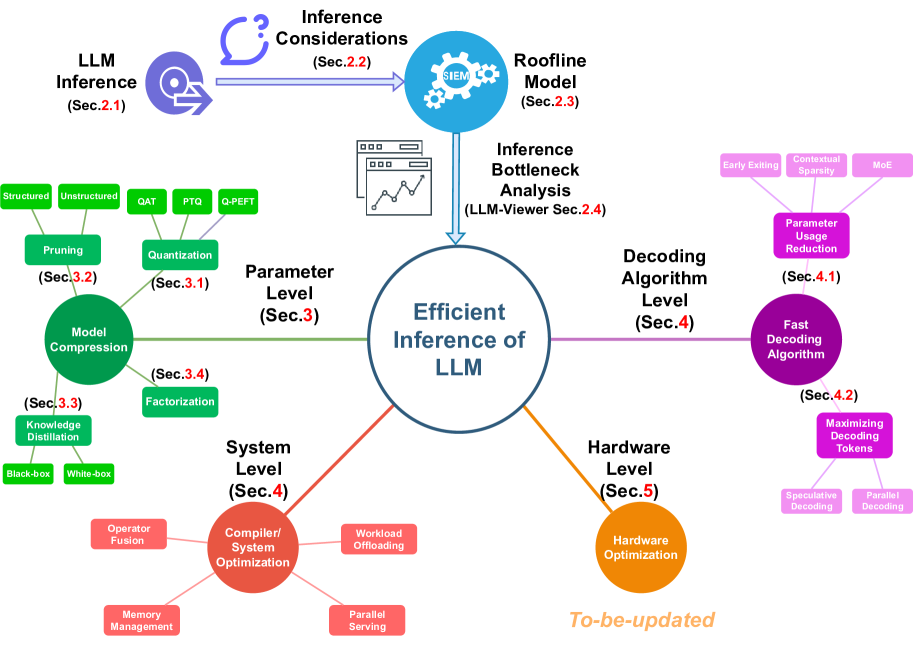
LLM Inference Unveiled: Survey and Roofline Model Insights - 知乎
Top NVIDIA GPUs for LLM Inference | by Bijit Ghosh | Medium
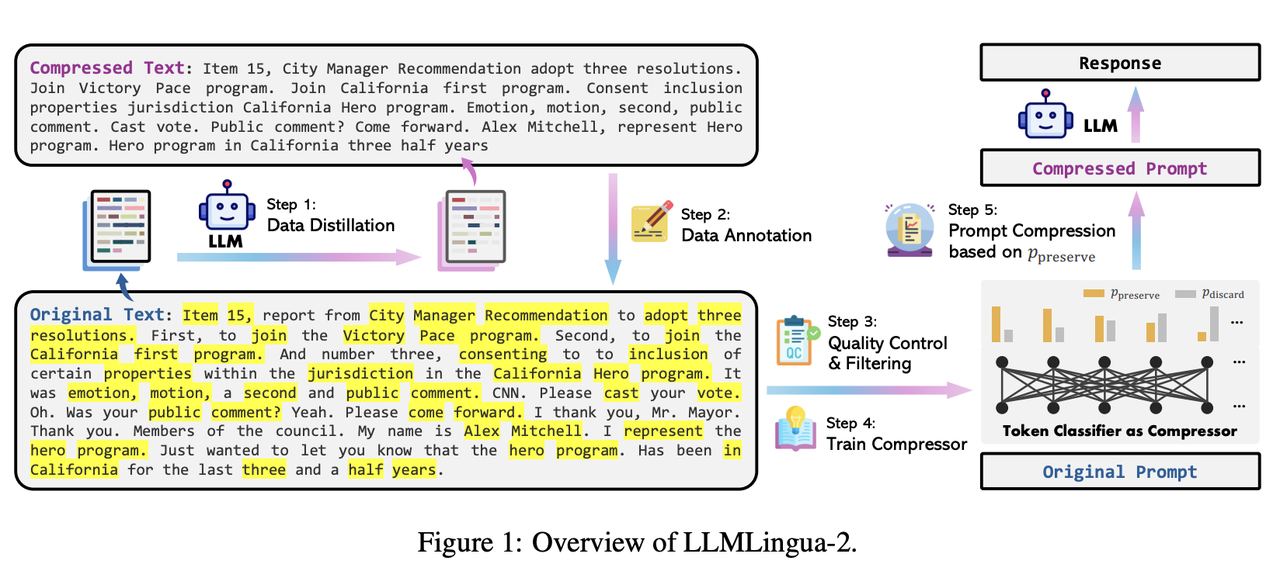
Illustration of the privacy-preserving LLM inference. The LLM inference ...
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
LLM Inference Optimization Techniques | Clarifai Guide
LLM Inference Stages Diagram | Stable Diffusion Online
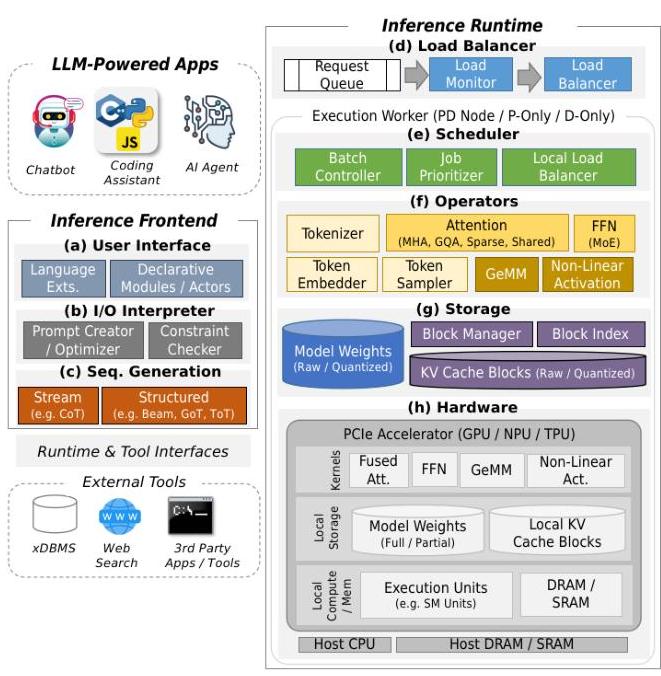
A Survey of LLM Inference Systems | alphaXiv
How continuous batching enables 23x throughput in LLM inference ...
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference - Hw-Sw Optimizations
LLM Inference Hardware: Emerging from Nvidia's Shadow
LLM Inference - NVIDIA RTX GPU Performance | Puget Systems
LLM Inference Optimization in Production: A Technical Deep Dive | by ...
LLM Inference Parameters Explained Visually
Automating Inference Optimizations with NVIDIA TensorRT LLM AutoDeploy ...
LLM Inference Benchmarking Guide: NVIDIA GenAI-Perf and NIM | NVIDIA ...
Energy-Efficient LLM Inference Strategies | PDF | Parallel Computing ...
A guide to LLM inference and performance
Introduction to LLM Inference Benchmarking | Yu-Chen Cheng's Blog
LLM Inference
Choosing the right GPU | LLM Inference Handbook
LLM Inference - Consumer GPU performance | Puget Systems
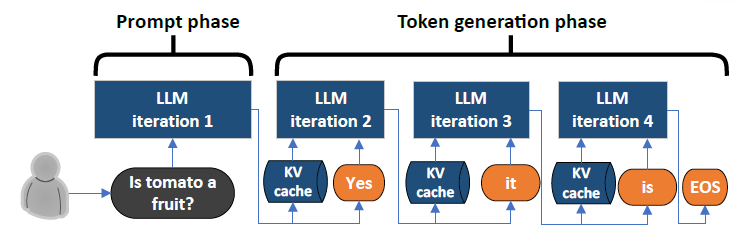
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
Why is LLM Inference Optimization Important in 2026?
S62797 - LLM Inference Sizing - Benchmarking End-to-End Inference ...
How does LLM inference work? | LLM Inference Handbook
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
Comparing the Top 6 Inference Runtimes for LLM Serving in 2025 - AIBtz.com
How LLM really works: From Training to Talking – The Power of Inference
A Guide to LLM Inference Performance Monitoring | Symbl.ai
What Is LLM Inference? Batch Inference In LLM Inference
How to Implement GPU-Based LLM Inference in AO
LLM Visualization Tool to Understand Inference - YouTube
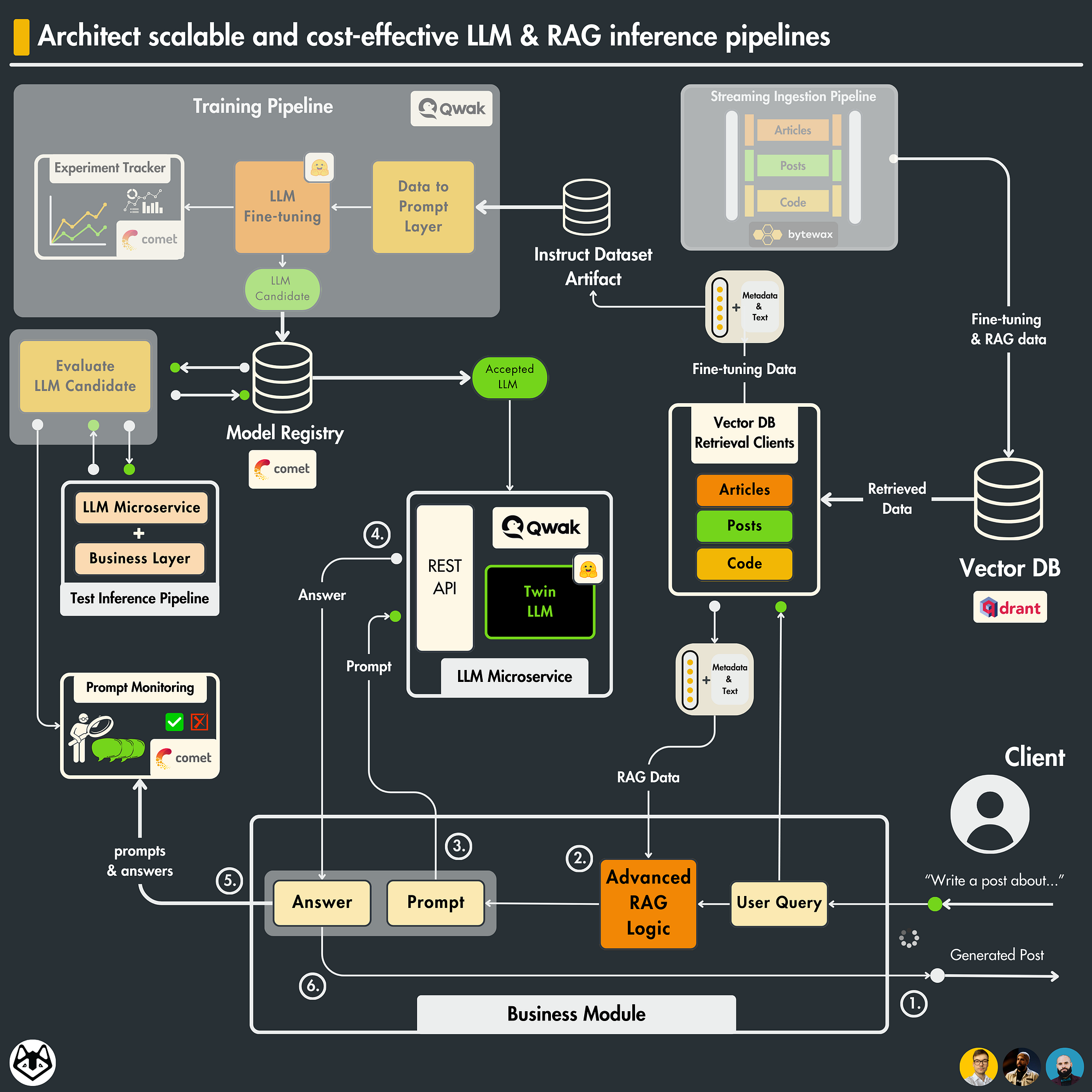
How to Architect Scalable LLM & RAG Inference Pipelines
How to Scale LLM Inference - by Damien Benveniste
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
Simplify LLM Deployment and AI Inference with a Unified NVIDIA NIM ...
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
(PDF) Improving the inference performance of LLM with code
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
LLM Inference Performance Benchmarking from Scratch
Benchmarking LLM Inference Backends
LLM Inference - EcoLogits
LLM Inference Benchmark - a Hugging Face Space by Inferless
This One Detail Explains Most of LLM Inference Performance - Coder Legion
LLM Inference Explained
LLM Inference Essentials
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
10 Strategies to Optimize LLM Inference Costs | thealpha posted on the ...
LLM Inference Optimization Techniques: Speed & Cost Guide 2026 | Hakia
Vidur: A Large-Scale Simulation Framework for LLM Inference Performance ...
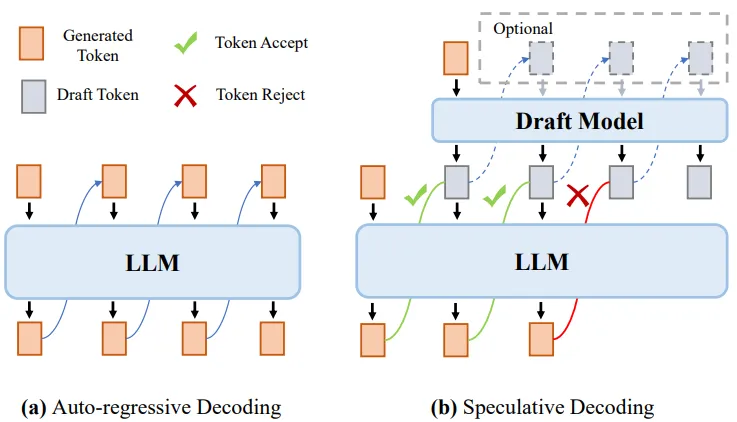
Accelerating LLM Inference - Tradeoffs, Design, and New Ideas
How to Build LLM Inference Pipelines for Enterprise Apps
High-performance LLM inference | Modal Docs
Tutorial LLM Finetune Inference - a Hugging Face Space by chtai
LLM Inference | Manifold
What Is LLM Inference? Process, Latency & Examples Explained (2026)
Optimizing AI Performance: A Guide to Efficient LLM Deployment
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
What is LLM Inference? • luminary.blog
What is LLM Model Inference?
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
(PDF) LLM-Inference-Bench: Inference Benchmarking of Large Language ...
Rethinking LLM inference: Why developer AI needs a different approach
6 Production-Tested Optimization Strategies for High-Performance LLM ...
Decoding LLM Inference: A Deep Dive into Workloads, Optimization, and ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
Nvidia claims first place in MLCommon's first benchmarks for LLM ...
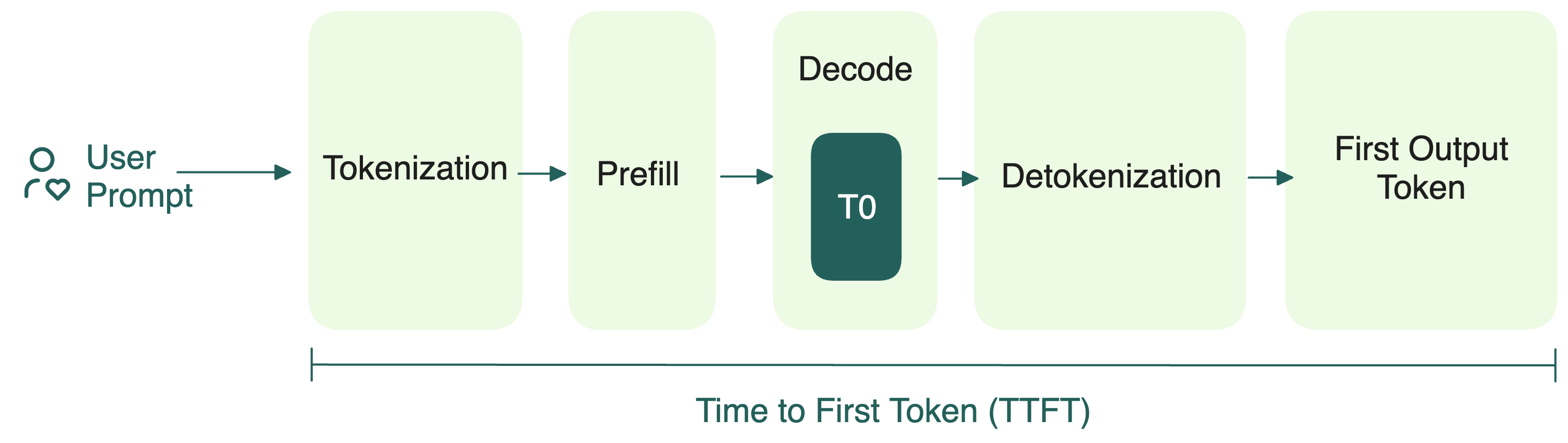
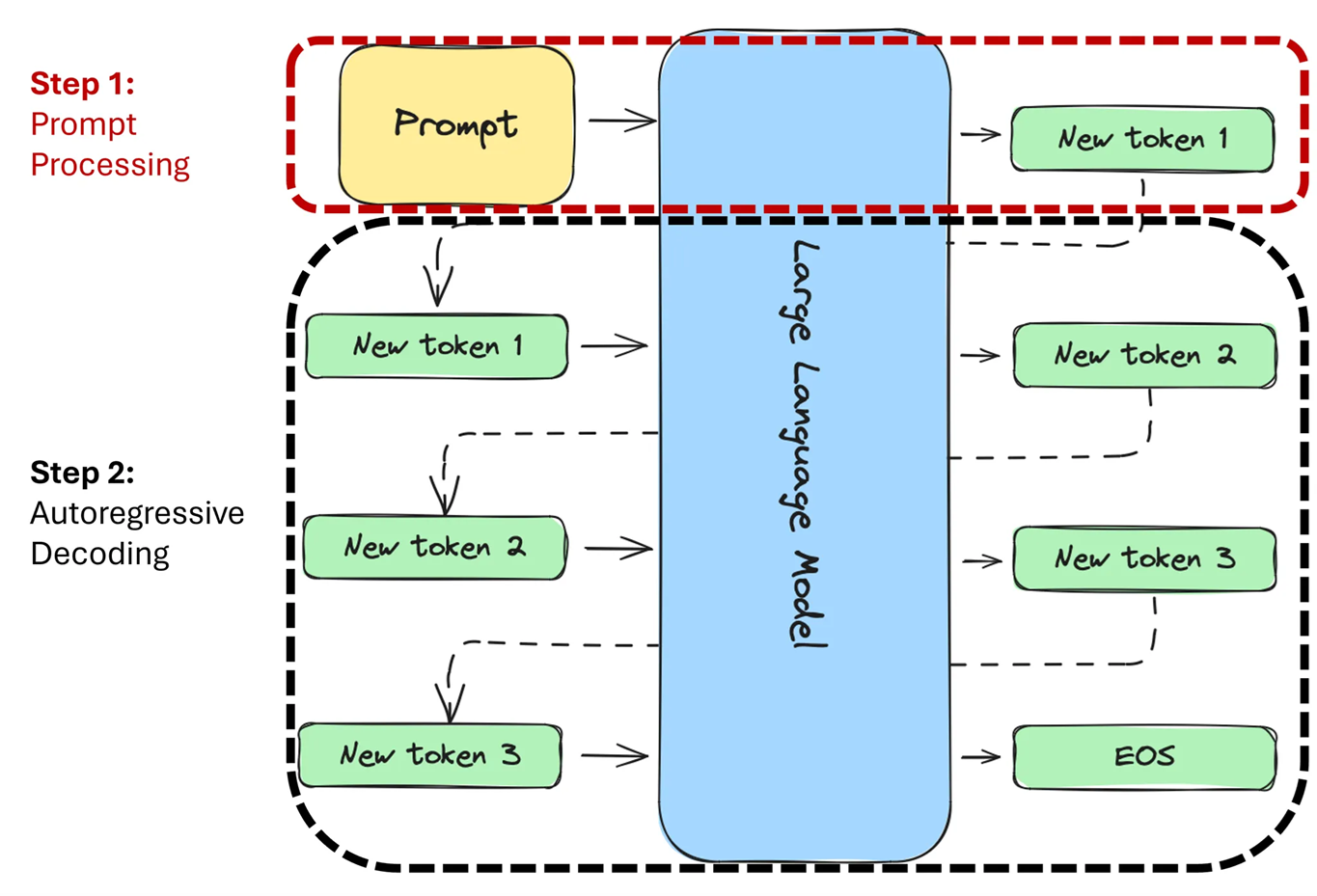
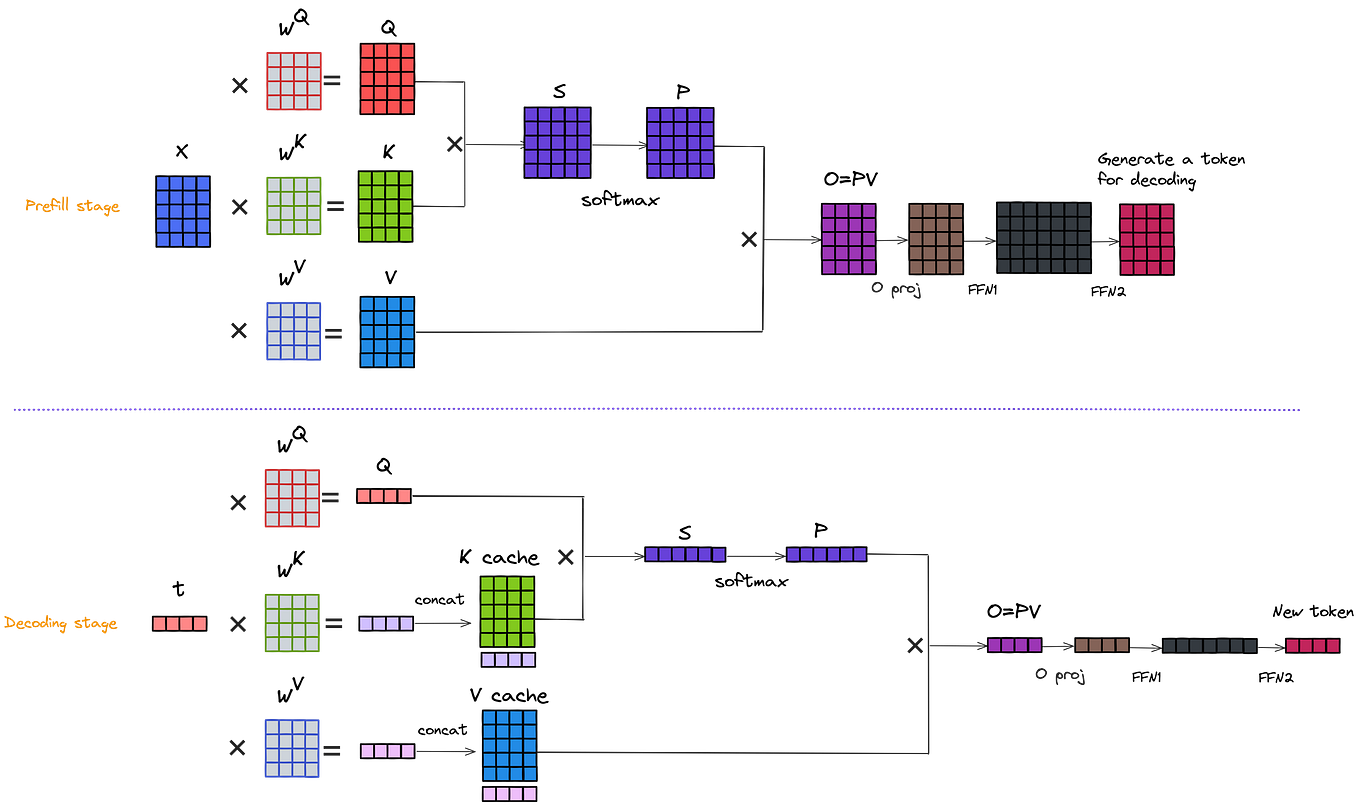
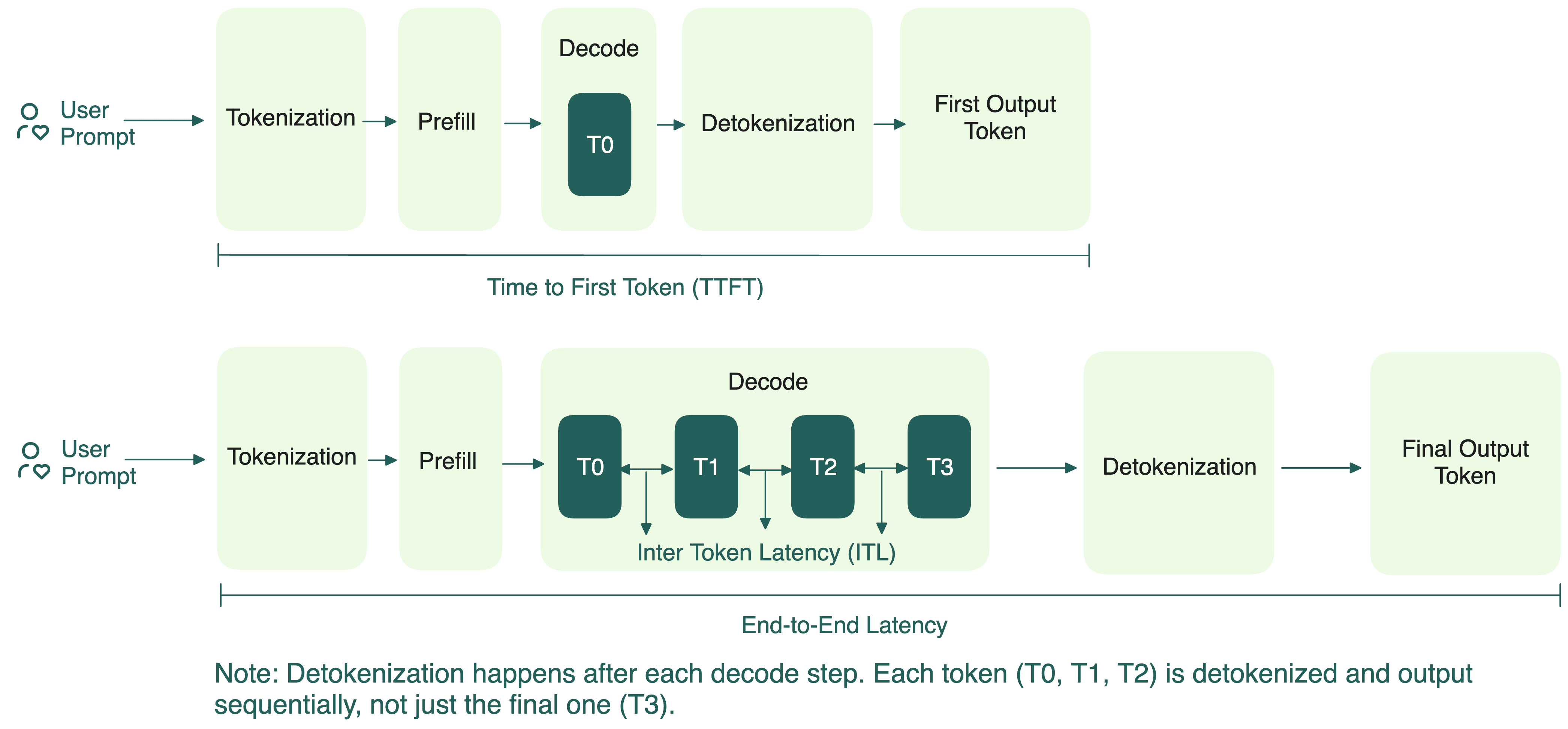
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
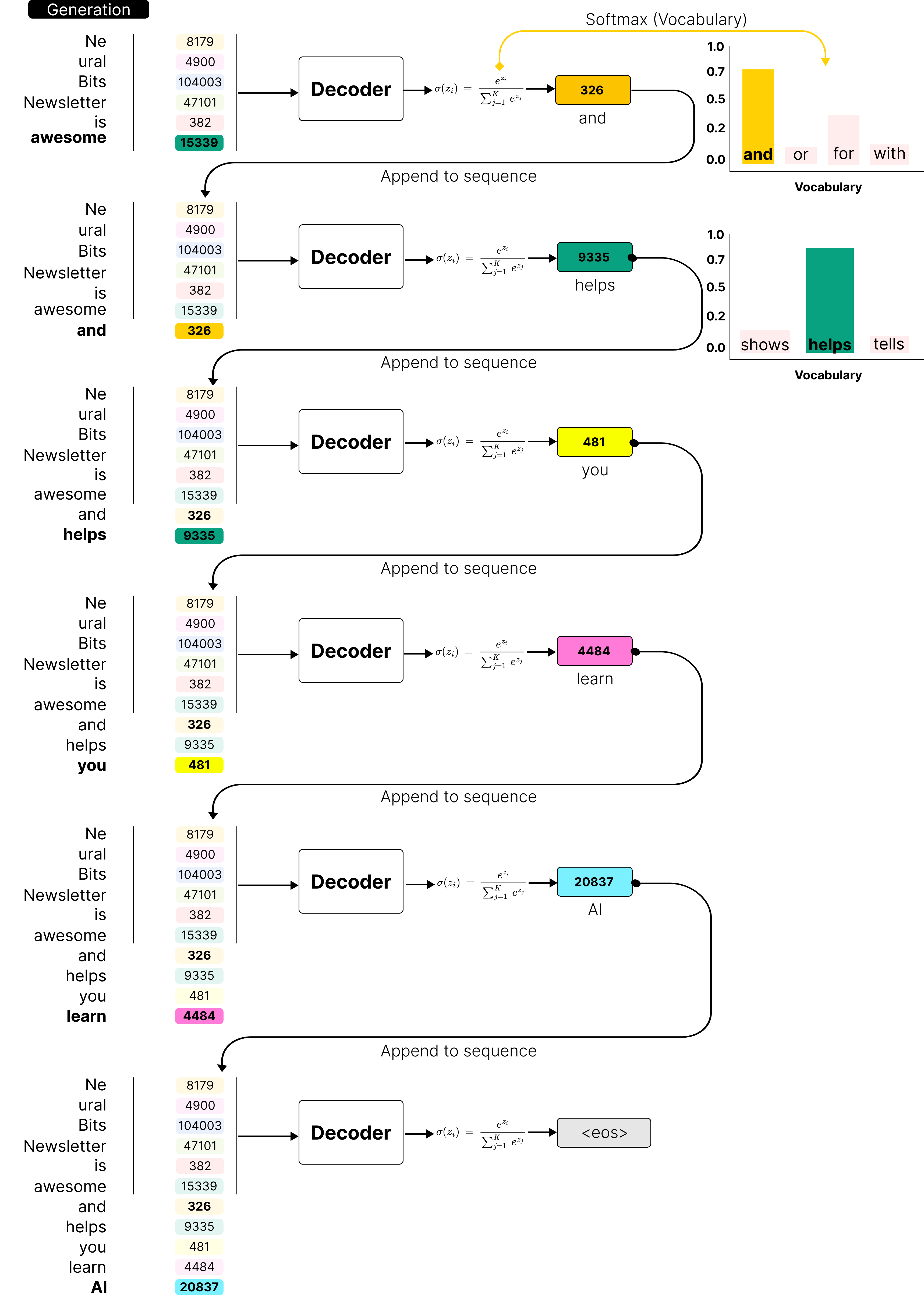
Understanding LLM Inference: How AI Generates Words | DataCamp
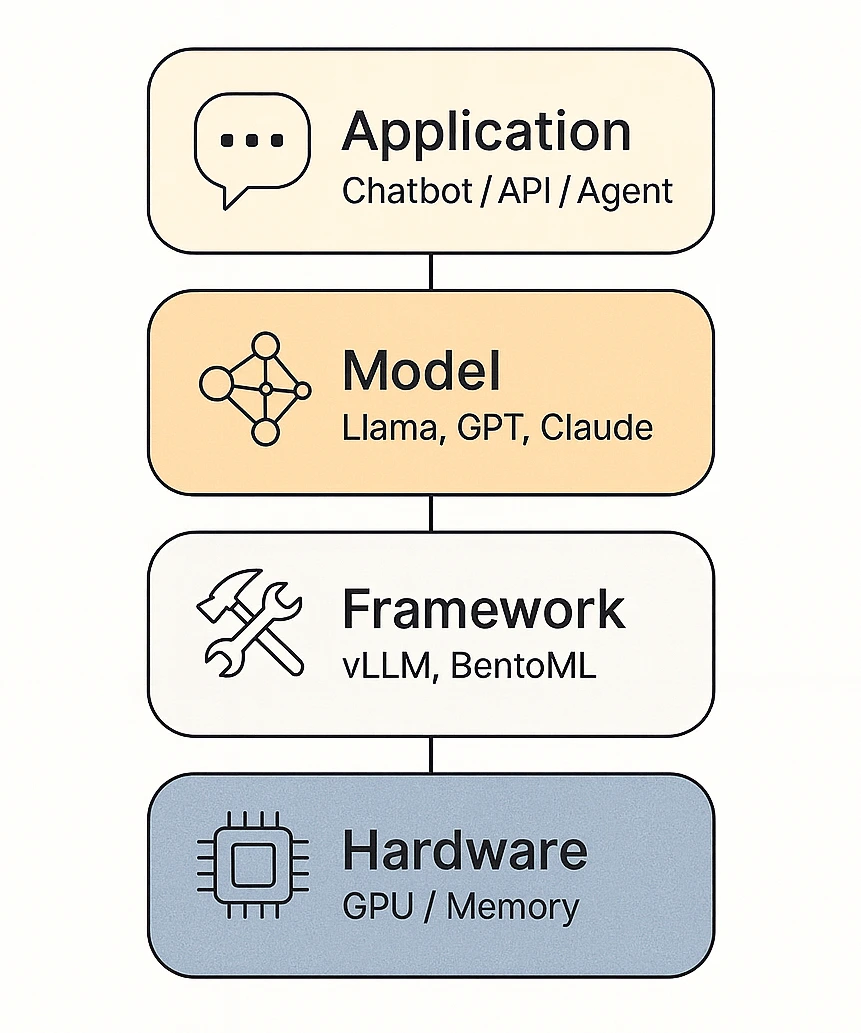
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
L40S GPU for AI and Graphics Performance | NVIDIA
The Future of Serverless Inference for Large Language Models – Unite.AI
Topic 23: What is LLM Inference, it's challenges and solutions for it
LLM Inference: Techniques for Optimized Deployment in 2026 | Label Your ...
Unlocking the Power of LLM Inferencing: Real-Time AI Insights and Solutions
Why Choose NVIDIA H100 SXM for Peak AI Performance
llm-inference · PyPI
GitHub - graphcore-research/llm-inference-research: An experimentation ...
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
Optimizing Large Language Model Inference: A Deep Dive into Continuous
physics-llm-inference/ch01 at main · Infatoshi/physics-llm-inference ...
(PDF) Towards Efficient Multi-LLM Inference: Characterization and ...



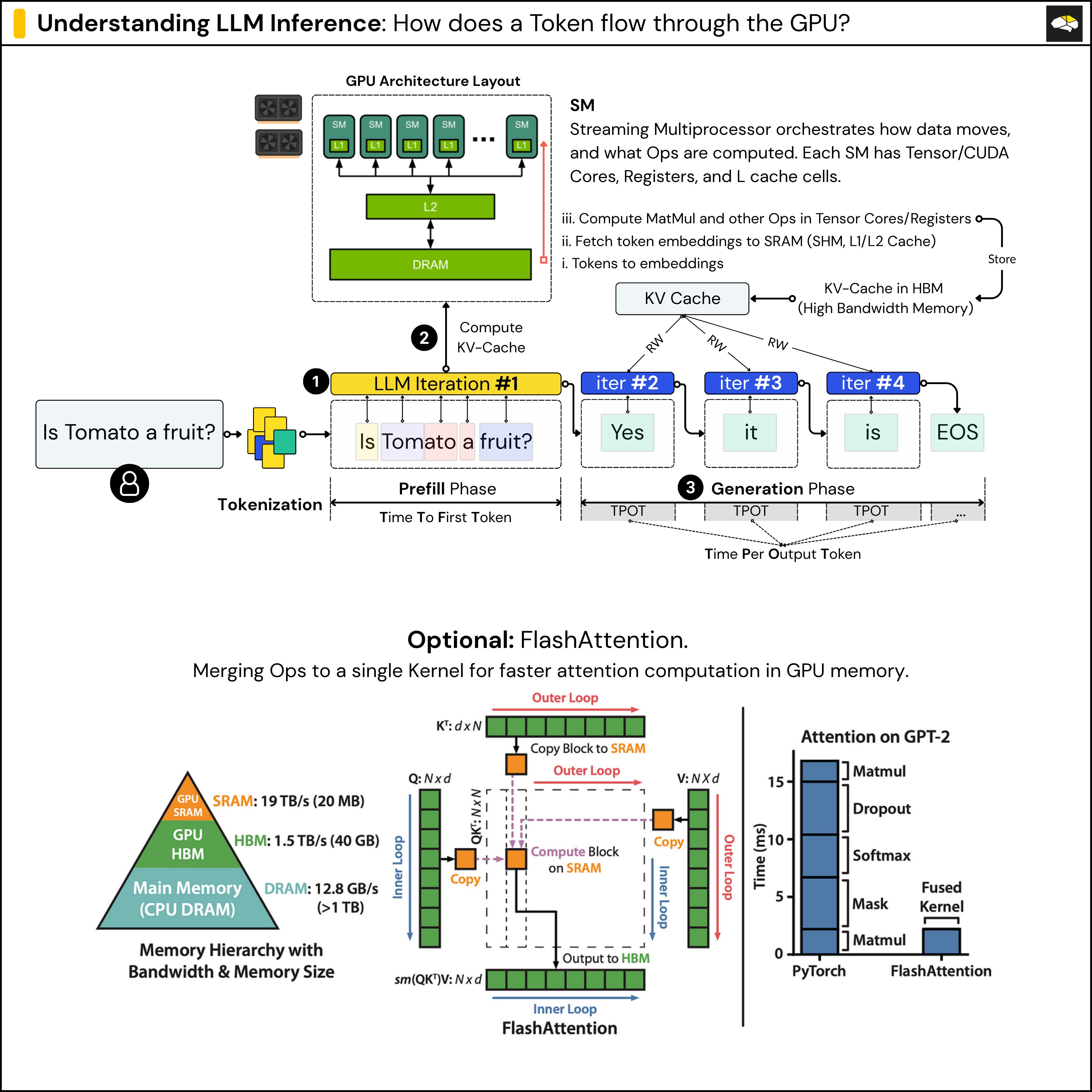
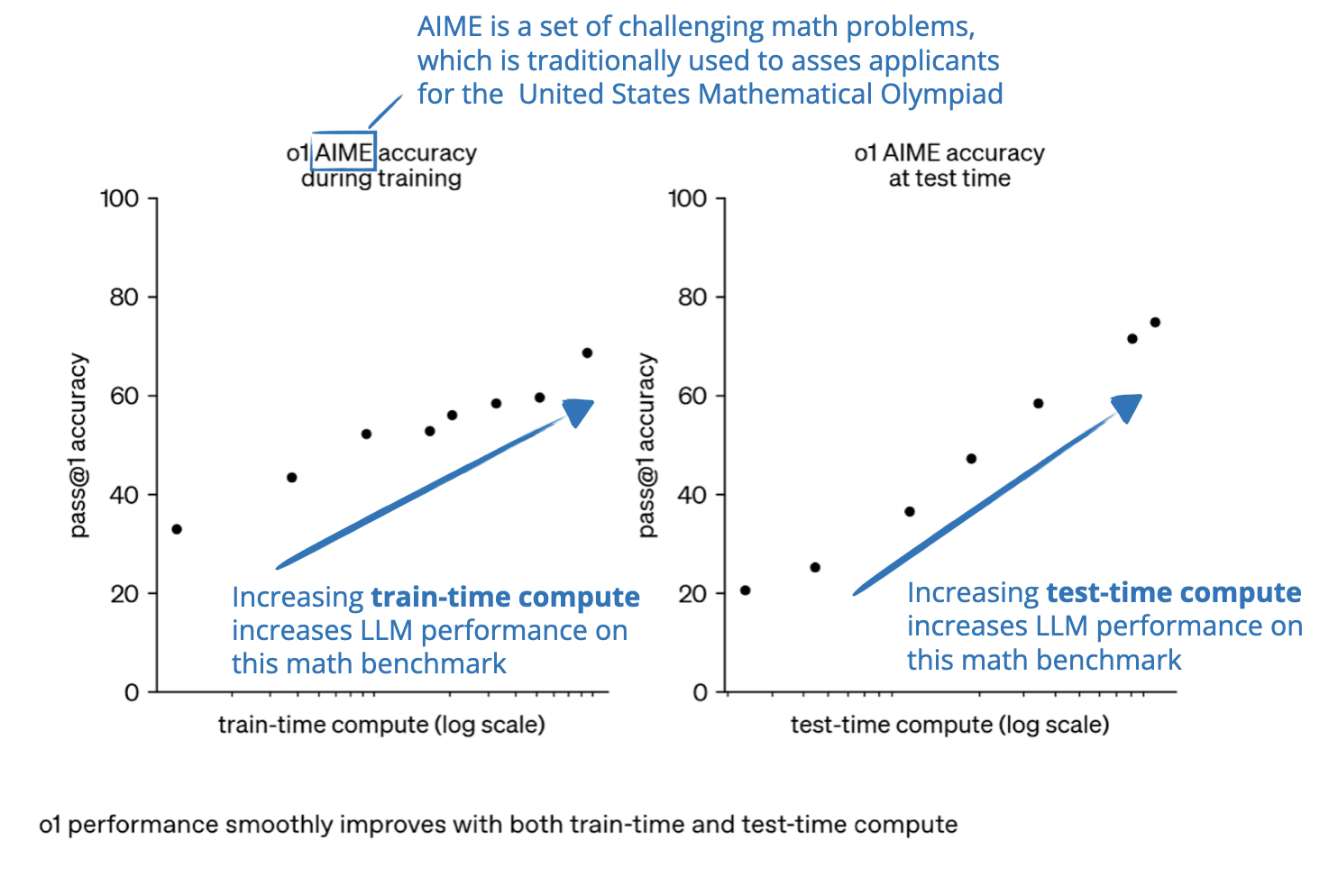
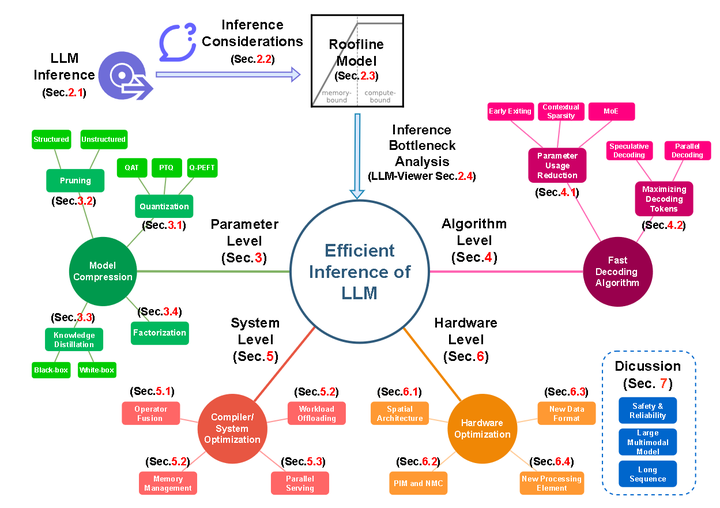
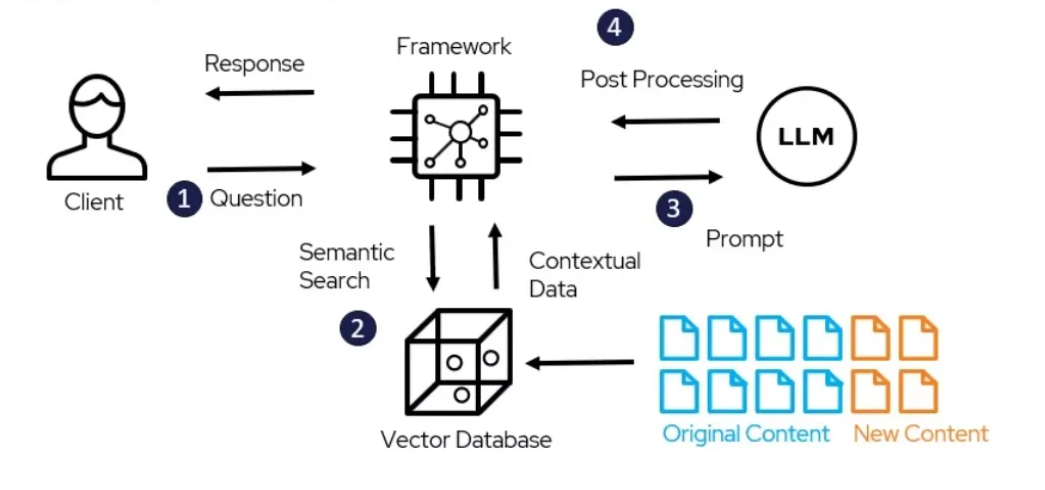




















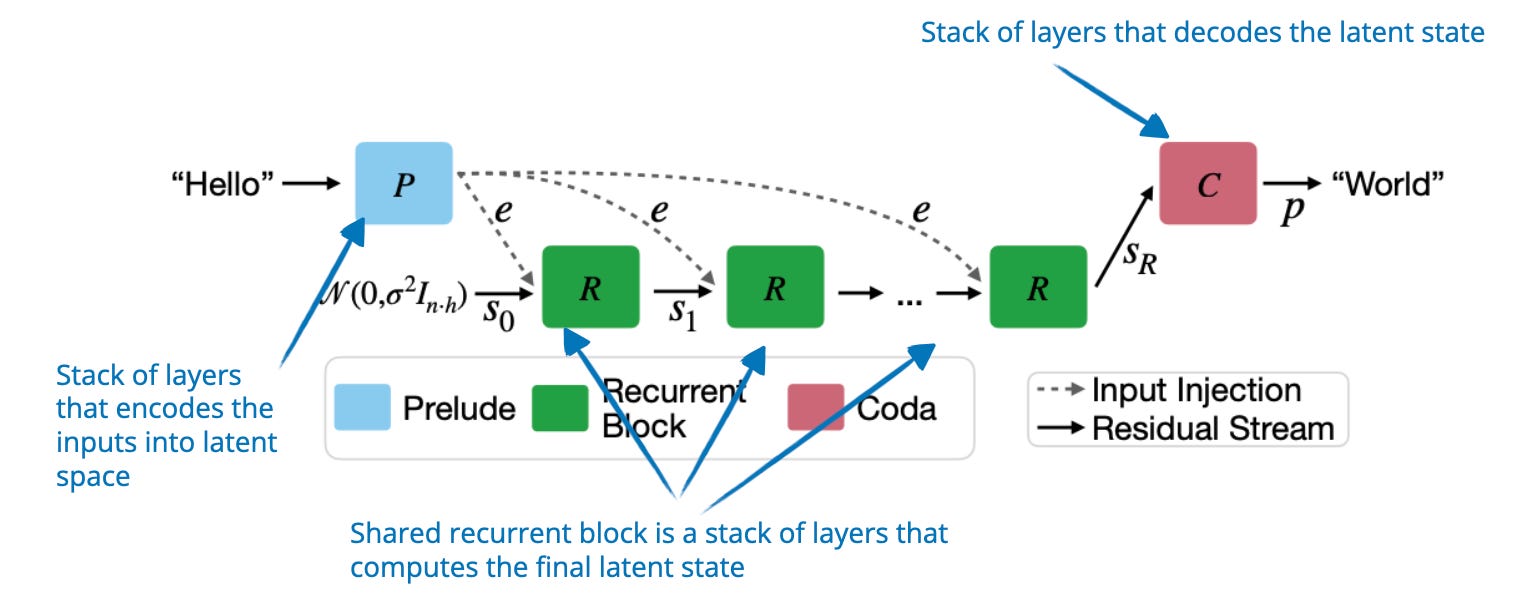




-png.png?width=4320&height=2160&name=AI%20Model%20Training%20vs%20Inference%20(1)-png.png)
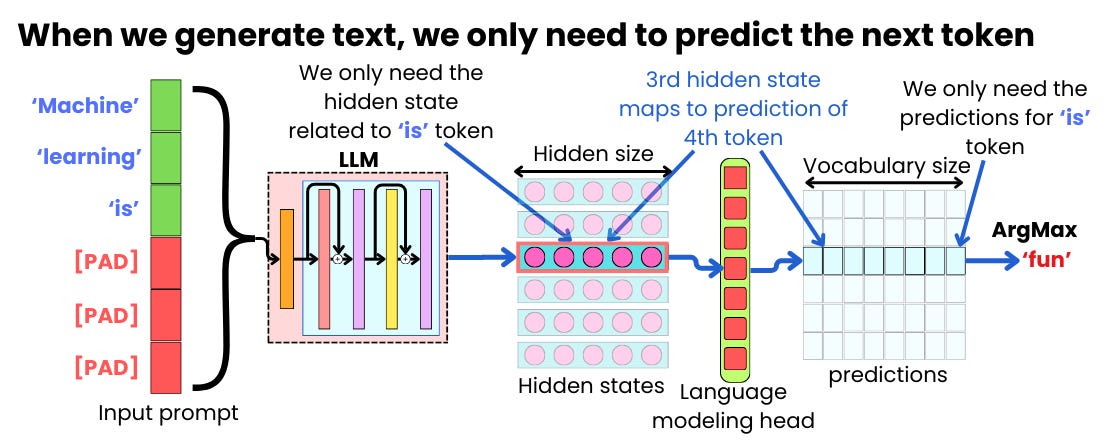
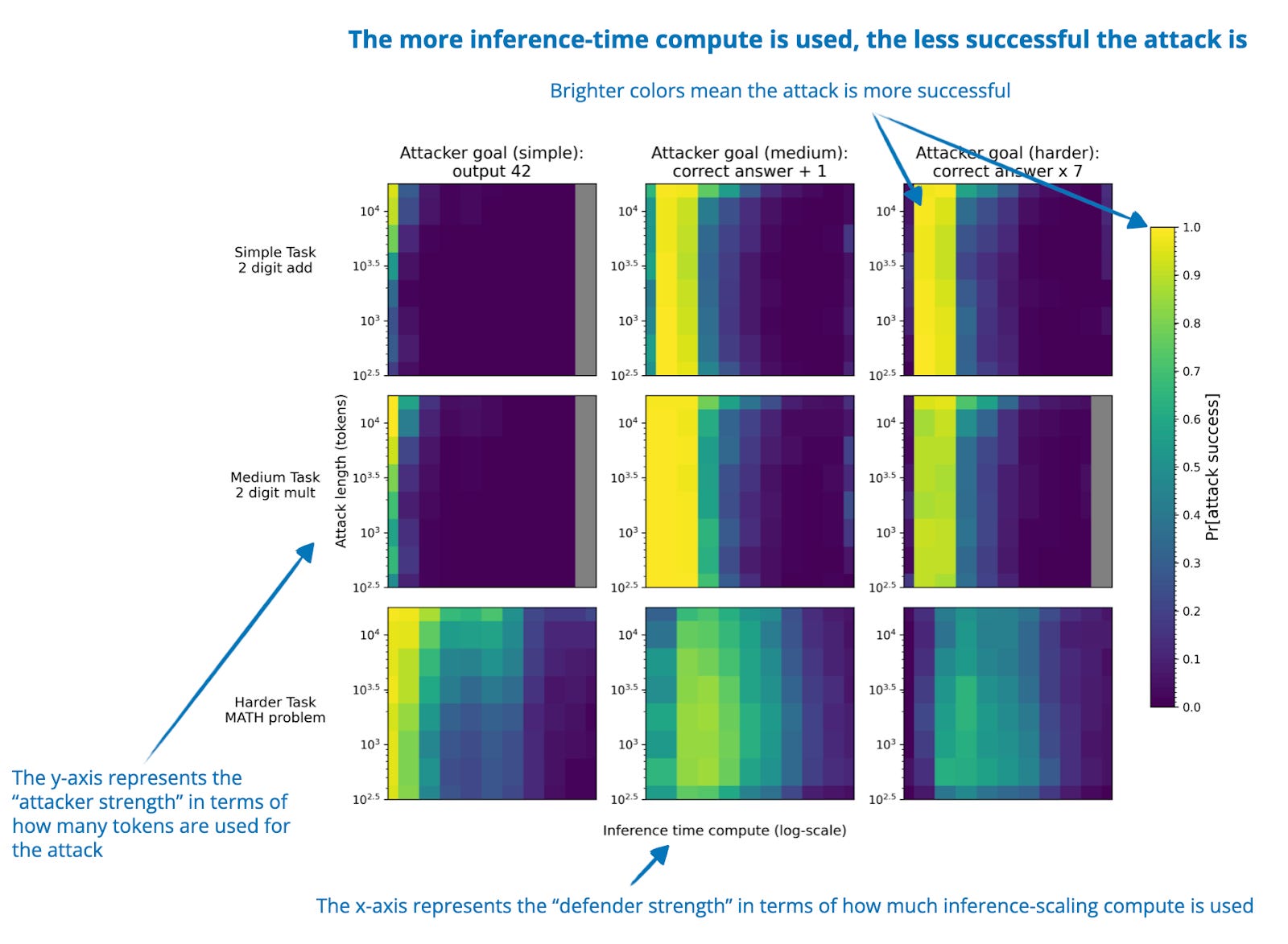




















.png)





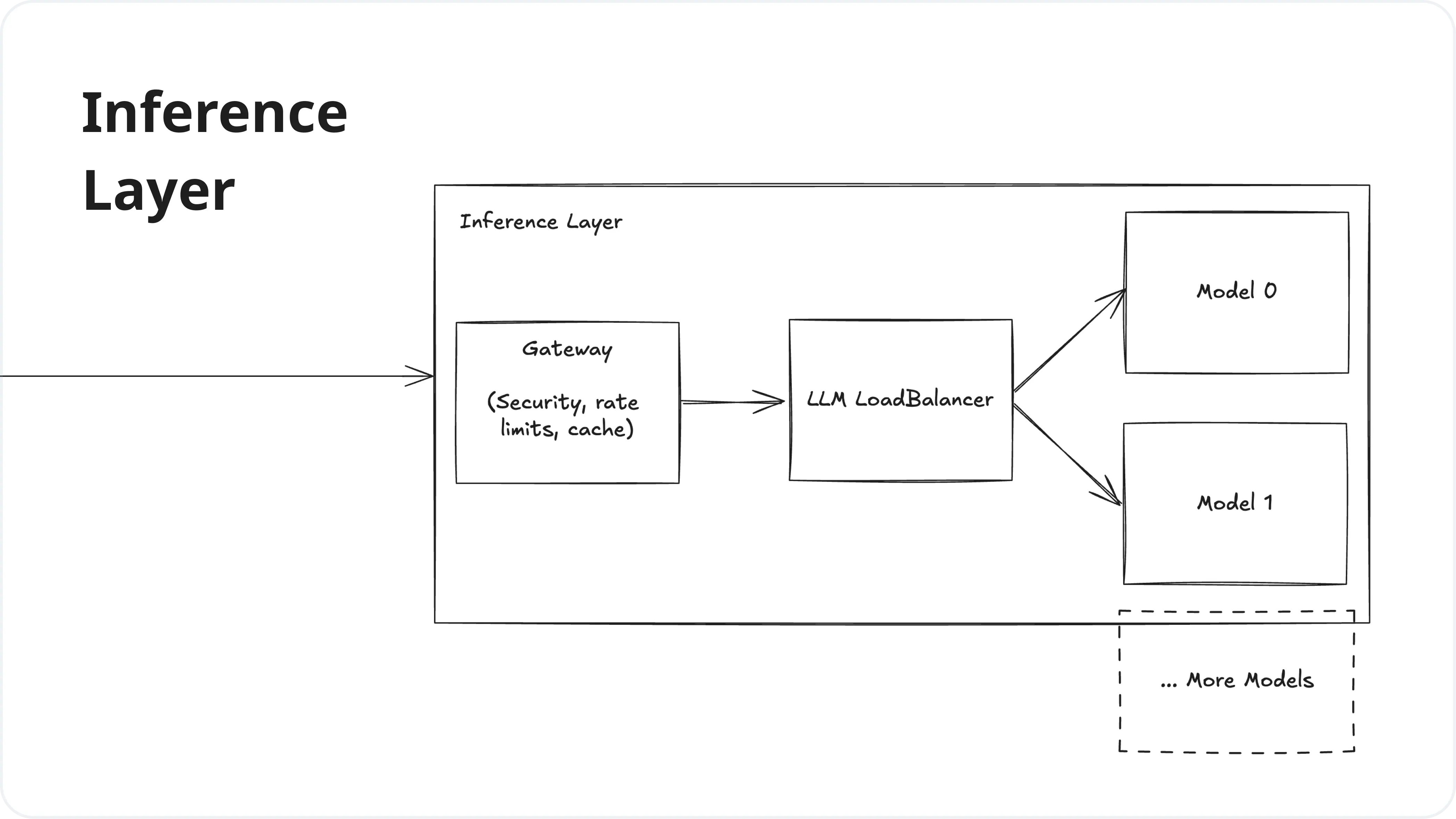







.png?width=1000&height=600&name=Challenges%20in%20LLM%20Training%20and%20AI%20Inference%20Infographics%20(1).png)

